概要
ASPEN.K2は,GPU/CUDAユーザ向けに自動チューニングされた高性能Level-2 BLASカーネルを提供します.
ダウンロード
| ASPEN.K2 バージョン 1.6p2 | ソースコード | |
|---|---|---|
| ASPEN.K2 バージョン 1.6p1 | ソースコード | |
| ASPEN.K2 バージョン 1.6 | ソースコード | |
| ASPEN.K2 バージョン 1.5p9 | ソースコード | |
| ASPEN.K2 バージョン 1.5p8 | ソースコード | |
| ASPEN.K2 バージョン 1.5p7 | ソースコード | |
| ASPEN.K2 バージョン 1.5p6 | ソースコード | |
| ASPEN.K2 バージョン 1.5p5 | ソースコード | 981183 byte |
| ASPEN.K2 バージョン 1.5p4 | ソースコード | 554978 byte |
| ASPEN.K2 バージョン 1.5p3 | ソースコード | 705153 byte |
| ASPEN.K2 バージョン 1.5p2 | ソースコード | 413497 byte |
| ASPEN.K2 バージョン 1.5p1 | ソースコード | 395769 byte |
| ASPEN.K2 バージョン 1.5 | ソースコード | 395637 byte |
| ASPEN.K2 バージョン 1.4p1 | ソースコード | 420285 byte |
| ASPEN.K2 バージョン 1.4 | ソースコード | 325324 byte |
| ASPEN.K2 バージョン 1.3p1 | ソースコード | 323049 byte |
リリースノート
1.6 : Apr. 6, 2017
- Support the double-double format; wsymv and uhemv.
- Support both static and shared library formats: libaspen.a and libaspen.so.
- Support stream interface, ASPEN_setStream and ASPEN_getStream.
- Unify symv and hemv templates into hesymv template.
- Tune up the kernel by introducing internal fma2 and add2 operations.
- Minor modification for the parametre search scripts.
- Gemv kernels have been obsolated from this version.
1.5p9 : Nov. 25, 2016
- Support Complex functions; zhemv and chemv.
- Fix a severe bug in the unexpcted overtook store operation onto L2 by atomic operations due to TLB miss or other issues, it was very rarely happened in 1.5p8.
- Minor modification for parametre search scripts.
1.5p8 : Jul. 21, 2016
- Modify the block-grid shape as a two-dimensional grid.
- Simplify the compilation process which is done for each sm_(20,30,…).
- Modify the Makefile rules to reduce the compliation time.
- Exprimental support of CUDA 8.0 and pascal architectures (sm_(60,61,62)).
- Exprimental support of half precision of Level1 BLAS.
1.5p7 : May 20, 2016
- Loop re-structured technique is employed for symv kernels.
- Correct the capacity of the shared memory for the Maxwell architecture.
- Tuning shell scripts is slightly changed so as to allow a wider-ranged parameters space,
max{32, BASE(=VX*m)} <= BLOCK_SIZE*VX <= 512,
32 <= BLOCK_SIZE(=32*k) <= 256, 1<=VX<=8,
and 1 <= BASE(=VX*m) <= 192.
In addition, multiplicity >= 2.
Also user can choose whether rough and full search modes by the environment variable ASPEN_TUNING_LEVEL. If ASPEN_TUNING_LEVEL equals to ‘ROUGH’ or ‘FULL’, the search mode is designated in rough search or Bruto-force search, respectively. BUT, the ROUGH mode yields acceptable good result in most cases. - Introduce ASPEN_ERROR_CHECK to control the error check during tuning process.
- Arrange the header files.
- Implement a couple of Level 1 BLAS routines such as axpy, scal, etc.
- Preliminary version of cu(Float|Double)complex for Level 1 BLAS.
1.5p6 : Nov. 13, 2015
- Minor change for symv kernels.
- Minor change for tuning shell scripts to reduce the number of parameter samplings.
- Assemble the latest benchmark results on bench/logs.
- Support CUDA 7.5.
1.5p5 : Aug. 31, 2015
- Minor change for symv kernels so as not to fall in deadlock.
- Minor change for tuning shell scripts to reduce the number of parameter samplings.
1.5p4 : Apr. 30, 2015
- Minor change for symv kernels to improve their performance.
- Minor change for tuning shell scripts.
- Reformat the source files by the indent mechanism of the emacs C++-mode.
1.5p3 : Mar. 9, 2015
- Minor change for [ds]symv_l kernels to reduce the register consumption.
- Obsolate the L+U algorithm adpopted in [ds]symv_u kernels.
- Bug fix for [ds]gemv_n in case of non-square matrices.
- Support both CUDA 7.0RC and CUDA 6.5 on which ‘sm_52’ is available.
- Bug fix for the occupancy calculation in case of the Fermi architecture.
1.5p2 : Feb. 9, 2015
- Bug fix for an infinite loop trap in [ds]symv_l kernels.
- Minor change for [ds]symv_l kernels.
- Invalidate the Tesla kernel implementations,
- Modify Makefile and shell scripts not to use the deviceQuery command.
1.5p1
- Modify [ds]symv_[lu] kernels to support the sumup routine via shared memory.
1.5 : Dec. 19, 2014
- Add ‘L’ower triangular matrix format for [ds]symv.
- Modify tuning scripts of [ds]symv_[lu].sh to support full multiplicity upto 32 for the Maxwell architectures.
1.4p1
- Experimental support for sm_50 (Maxwell aka GM107) and a brandnew architecture refered to sm_52 (Maxwell2 aka GM204).
- Minor bug fix for a script which generates if-then rules to switch parameters.
- Minor change for SYMV kernel in oder to avoid deadlock.
- Bug fix in the occupancy calculation for larger shared memory (32/48KB).
- Rewrite Makefiles’ rules.
1.4 : Sep. 12, 2014
- Divide the Kepler codes into sm_30(Kepler) and cc_35(Kepler2).
- Minor bug fix in [ds]symv.sh and minor change in [ds]symv kernels.
- Minor change in the searching algorithm for [ds]symv by 3-step algorithm.
- Modify the primal Makefile and remove redundant source files.
- Bug fix in the occupancy calculation for the Fermi architecture.
1.3p1 : Aug. 26, 2014
- Minor bug fix.
- From this version, ASPEN.K2 release as Open Source Software.
1.3
- Minor bug fix and vector2 load is newly applied for SYMV kernel.
1.2
- New kernel implementation for SYMV is introduced.
1.0
- The current release supports some of the Level 2 BLAS kernels for the CUDA environment focused on the Fermi and Kepler architectures with CUDA version 5.5 later. (Maxwell architecture and CUDA prior to 5.0 are not officially supported.) Available functios are as follows.
- [DS]GEMV, both operation for normal ‘N or n’ and transposition ‘T or t’.
- [DS]SYMV, only the upper ‘U or u’ triangular matrix format.
- Other than above mentioned modes are proceeded by the CUBLAS library.
Benchmark
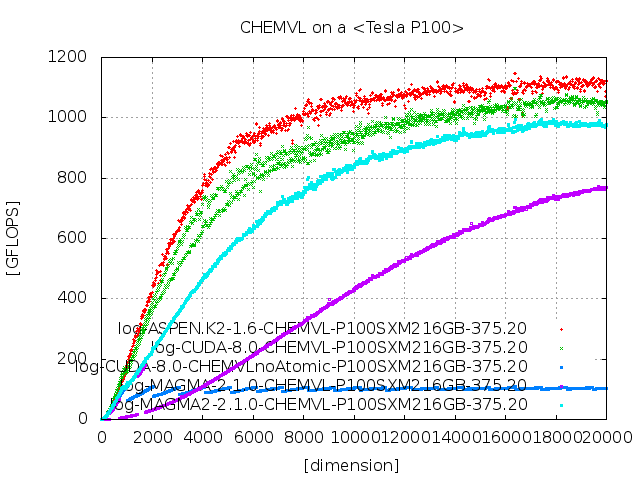
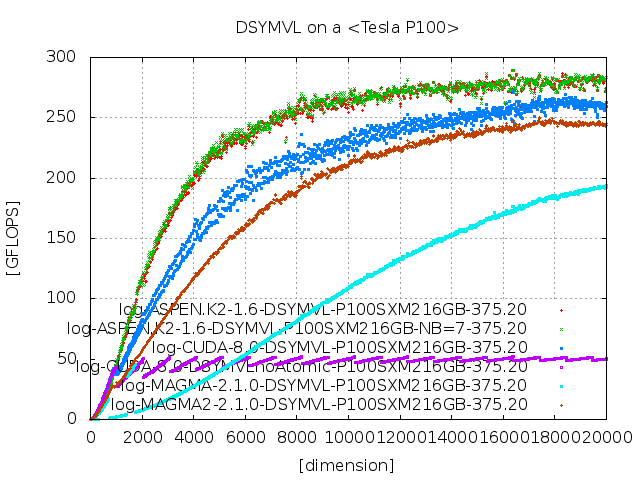
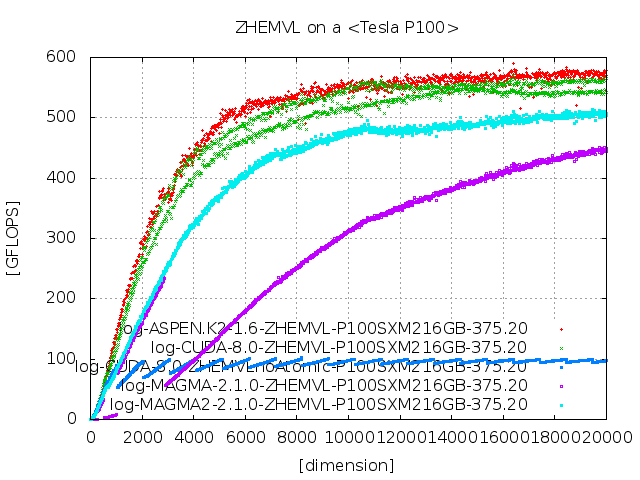
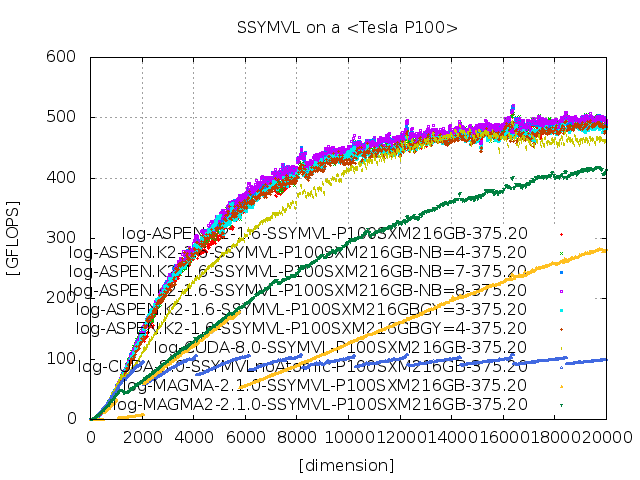
参考文献
今村俊幸, 椋木大地, 山田進, 町田昌彦 「SYMV・GEMVルーチン群のマルチGPU化とその評価」, 情報処理学会研究報告 「ハイパフォーマンスコンピューティング(HPC)」, Vol. 2015-HPC-151, No. 13, 2015年9月 (in Japanese).
今村俊幸, 椋木大地, 山田進, 町田昌彦 「CUDA-xSYMVの実装と評価」, 情報処理学会研究報告 「ハイパフォーマンスコンピューティング(HPC)」, Vol. 2014-HPC-146, No. 14, 2014年10月 (in Japanese).
T. Imamura, S. Yamada and M. Machida, “A High Performance SYMV Kernel on a Fermi-core GPU”, High Performance Computing for Computational Science – VECPAR 2012, Lecture Note in Computer Science (LNCS) 7851, pp. 59–71, 2013.
T. Imamura, “ASPEN-K2: Automatic-tuning and Stabilization for the Performance of CUDA BLAS Level 2 Kernels”, 15th SIAM Conference on Parallel Processing for Scientific Computing (SIAM PP12), Seattle, USA, Feb. 15-17, 2012.
今村俊幸,内海貴弘,林熙龍,山田進,町田昌彦, 「Fermi, Kepler複数世代GPUに対するSYMVカーネルの性能チューニング」, 情報処理学会研究報告,「ハイパフォーマンスコンピューティング(HPC)」,Vol. 2013-HPC-138,No. 7,pp. 1–7,2013年2月14日, 第138回ハイパフォーマンスコンピューティング研究発表会(HPC138),芦原温泉清風荘,2013年2月21-22日.