


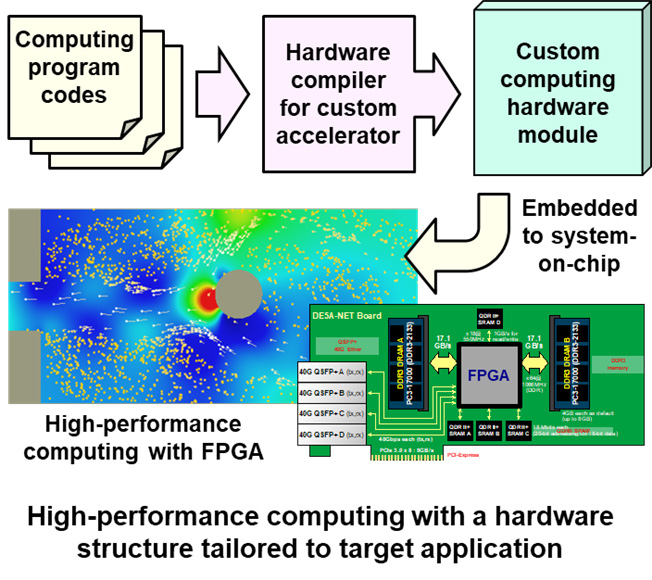
To achieve high-performance computing with the K computer, we need to use more than 80,000 networked computing nodes in a way that they cooperate with each other using communication data. However, the overall performance may be degraded by the considerable overhead required for global communications and synchronization among the nodes. We are developing computing accelerators to achieve large-scale processing with less performance degradation by introducing a new parallel computing model based on a “Data-Flow” model with localized communication and synchronization. Also, we are developing data-flow accelerators where custom-computing circuits are automatically generated by a high-level synthesis compiler for each target application. Such specially customized hardware structures allow us to achieve high performance processing even for those applications which conventional CPUs are not good at handling. These research results are helping advance usage of the K computer, as well as aiding exploration of new computing models and new architectures for future supercomputers.

- 2017
Team Leader, Processor Research Team, AICS, RIKEN (-present) - 2006
Visiting Researcher, Imperial College,London - 2005
Associate Professor, Graduate School of Information Sciences, Tohoku University - 2001
Assistant Professor, Graduate School of Information Sciences, Tohoku University - 2000
Assistant Professor, Graduate School of Engineering, Tohoku University - 2000
Graduated from Computer and Mathematical Sciences, Graduate School of Information Sciences, Tohoku University
