Improving the Performance and Productive Programming Environment for Exascale and Beyond
We are researching and developing parallel programming models and a new programming language to exploit the full potential of large-scale parallelism on the K computer, as well as working to increase productivity of parallel programming. The new programming language, called XcalableMP (XMP), is based on the PGAS (Partitioned Global Address Space) model, which was originally designed by the Japanese HPC language research community. We are working on a reference XMP compiler, the Omni XMP compiler, and have deployed it on the K computer for users, where it has several optimizations. We are also conducting a performance study of the PGAS language, as well as developing an extension for an accelerator cluster for use beyond the K computer. As for performance tuning tools for large-scale scientific applications running on the K computer, we have ported the Scalasca performance-tuning and analysis tool and we are examining its potential.
Regarding improving the performance, and productive programming model, we are working on a new version of XcalableMP: XcalableMP 2.0; it will include support for large-scale many-core clusters by multitasking with the PGAS model. This programming model will reduce synchronization overhead, thereby eliminating time-consuming global synchronization; enable the overlap of computation and communication in many-core processing; and reduce communications overhead of the RDMA feature, We are also developing the Omni compiler as part of the infrastructure for source-to-source transformation for high-level optimization, and we are optimizing many core processing and wide SIMD for the post-K supercomputer.
Recent Achievements
XcalableMP received HPCC best performance awards at SC13 and SC14 In recent years our XcalableMP received the HPC Challenge Class 2 Award at SC13, and the HPC Challenge Class 2
Best Performance Award at SC14. The HPC Challenge Class 2 is a competition to determine the programming language that achieves the highest productivity and performance. The HPCC benchmarks are a set of benchmarks to evaluate multiple attributes of an HPC system: RandomAccess, Fast Fourier Transform (FFT), High Performance Linpack (HPL), and STREAM. All four have been implemented on the K computer using XcalableMP. In addition, the Himeno Benchmark, which is a typical stencil application, has also been implemented.
We submitted the results to the SC13 and SC14 HPC Challenge Benchmark Class2 Competition. In order to evaluate their performance, we used all K computer nodes to the maximum. We then fine-tuned the Omni Compiler for the K computer and for the HPCC benchmarks after SC13. The Figure below shows the performance results at SC14. We demonstrated that the performances of XcalableMP implementations are almost the same as those of the reference implementations by MPI. As a metric to measure productivity, the source lines of code of our implementations are smaller than those of the reference implementations using MPI. Through these implementations and performance evaluations, we demonstrated that XcalableMP improves productivity and performance.
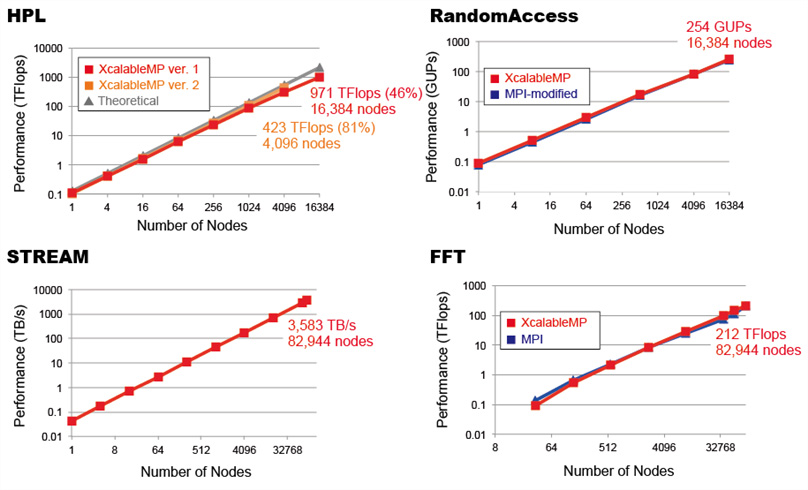
XcalableMP performance results measured against HPCC benchmarks (SC14)
Connections
Team Leader
Mitsuhisa Sato
- 2016
Professor(Cooperative Graduate School Program)and Professor Emeritus, University of Tsukuba (-present)
- 2014
Team Leader, Architecture Development Team of Flagship 2020 Project, AICS, RIKEN (-present)
- 2010
Team Leader, Programming Environment Research Team, AICS, RIKEN (-present)
- 2007
Director , Center for Computational Sciences, University of Tsukuba
- 2001
Professor , Graduate School of Systems and Information Engineering, University of Tsukuba (-present)
- 1996
Chief, Parallel and Distributed System Performance Laboratory in Real World Computing Partnership, Japan.
- 1991
Senior Researcher, ElectroTechnical Laboratory (-1996)
- 1984
M.S. and Ph.D. in Information Science, The University of Tokyo (-1990)
- Annual Report

FY2015 RIKEN AICS Annual Report
(PDF 690KB) - FY2014 RIKEN AICS Annual Report
(PDF 1.05MB)
- FY2013 RIKEN AICS Annual Report
(PDF 986KB)
- FY2012 RIKEN AICS Annual Report
(PDF 766KB)
- FY2011 RIKEN AICS Annual Report
(PDF 448KB)



