
- 2003
東京大学理学部情報科学科卒業 - 2005
東京大学大学院情報理工学系研究科コンピュータ科学専攻修了 - 2006
東京大学情報基盤センター助手(後に助教) - 2010
東京大学大学院情報理工学系研究科コンピュータ科学専攻修了、博士(情報理工学) - 2010
株式会社日立製作所 - 2012
AT&T Labs. 客員研究員 - 2017
AICS利用高度化研究チームチームリーダー(現職)



当研究チームのミッションはスーパーコンピュータにおけるプログラミングの生産性を高めることである。データ処理や人工知能などの新しい技術に注目が集まる中、スーパーコンピュータにおけるプログラム生産性の重要性は高まっている。
なぜなら、スーパーコンピュータには、データの取得が難しい現象をシミュレーションによって仮想的に発生させる、あるいは人工知能を用いた社会実験を安全に行う環境を提供するなどの新しい役割が期待されており、この期待に応えるためには、多種多様な装置や現象をシミュレーションするプログラムを短時間で開発することが求められるためである。
当チームはモデル記述言語、データ処理基盤、機械学習フレームワークなどの開発、実行環境をスーパーコンピュータ上に整備した上で、これらを接続するために必要な技術を研究開発する。現在、「京」は、Fortran などのプログラミング言語を用いて計算手順を記述することにより利用されるのが通常であるが、本チームは、シミュレーション対象機器などの動きを数式に近い形で与える言語やGUI を用いて、シミュレーション、データ処理、あるいはそれらの融合から成る大規模な計算を容易に実行できる環境の実現をめざす。また、製品からサービスに移行している産業界の動向も踏まえ、アカデミアの成果物であるソフトウェアをサービスの形で普及させるべく、社会的に必要な仕組みの検討も行う。
モデル記述言語の活用
当研究チームはモデル記述言語をスーパーコンピュータで活用することをめざす。シミュレーションの最大の問題は、シミュレーションの定義に高度な専門性と膨大な時間を要することである。産業界の一部ではシミュレーションを簡潔に記述できるモデル記述言語が利用されているが、一般的には、これらを用いて作成されたプログラムは最適化や並列化が十分でなく、解ける問題の規模や精度が限られる。我々は、モデル記述言語をスーパーコンピュータ向け数値ライブラリに接続するなどの方法で、最低限の人間の手助けにより、利便性と問題規模の両立を実現する手法を開発する。
シミュレーションとデータ処理の融合基盤
上記のモデル記述言語に、さらにデータを扱う仕組みを結合する。データ処理については、データ解析で有名なHadoop やSpark、あるいは人工知能分野で研究がさかんな各種深層学習フレームワークなど、多くの既存技術が存在する。しかし、実行機構の違いなどから現状ではシミュレーションとの併用は容易でない。当研究チームではこれらを接続し、理論的に構築したモデルと機械学習で構築したモデルを併用するような複雑なシミュレーションであっても、単一の環境で最低限のプログラミングにより実行できる環境を整備する。
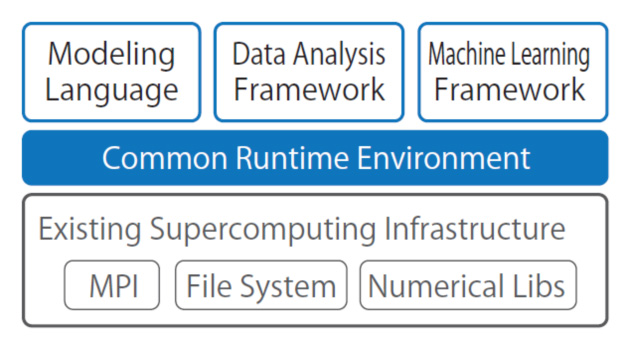
Developing an end-to-end solution from simulation modeling to data processing
