
- 2000
東北大学大学院情報科学研究科情報基礎科学専攻修了 - 2000
東北大学大学院工学研究科助手 - 2001
東北大学大学院情報科学研究科情報基礎科学専攻助手 - 2005
東北大学大学院情報科学研究科情報基礎科学専攻助教授(2007年より准教授) - 2006
インペリアルカレッジロンドン客員研究員 - 2017
AICS プロセッサ研究チームチームリーダー(現職)



「京」やポスト「京」では、ネットワークで接続された膨大な数の計算ノードが相互に通信し合いながら手分けして並列に処理を進めることにより、大規模な計算を高速で実行する。しかし、ノード数が多くなるにつれて通信や同期に時間がかかり、全体として計算機の規模に見合った性能を実現しにくくなる。また、昨今の大規模並列計算機は、複数のマルチコアプロセッサからなる共有メモリ型ノードを分散メモリ型並列計算機として相互に接続したものであり、その複雑な構造のために、性能を十分に引き出すためのプログラミングや最適化は困難で時間のかかる作業となっている。これに対し、当研究チームでは、処理単位である「タスク」の依存グラフとして記述した計算問題を自動的に並列化し、ハードウェア資源を適切に割り当てながら実行を進める「データフロー型」並列計算モデルの開発に取り組んでいる。依存するタスク間に限定された局所的なデータ移動や同期に基づくことにより、システム規模に応じた性能が容易に得られるようになる。
一方、機械学習やビッグデータ処理といった新しい種類の計算問題を高性能かつ低電力で実行するための計算加速機構の研究にも取り組んでいる。アルゴリズムを専用ハードウェア構造に変換し、それを回路再構成可能デバイスにプログラムし実行することで、従来のプロセッサが苦手とする処理の高速化をめざしている。
専用計算加速機構を生成するコンパイラを開発し低電力高性能数値計算を実現
ムーアの法則と呼ばれる半導体技術の進展が減速・停滞してきたことから、近い将来、メニーコア型の汎用マイクロプロセッサでは計算性能の向上が困難になるといわれている。この問題を解決する方法の一つとして、対象計算問題を専用の回路に変換し、回路再構成可能デバイスFPGA を用いて専用の計算加速機構を実現する試みが注目を集めている。これまで、数式による独自言語のプログラムから専用の計算加速機構ハードウェアを生成するコンパイラと、FPGA を用いてそれを動作させるための処理系の開発を行った。浅水方程式に基づく津波シミュレーションに対して本処理系を適用したところ、単一のFPGAにより、GPUによるシミュレーションと比べておよそ2 倍の計算性能、および8 倍の電力性能比を実現した。これは、対象とする計算問題に特化したメモリシステムやデータフローグラフに基づく計算パイプラインにより、効率よく演算を実行できる回路を生成できたためである。このほかにも、数値データ列をリアルタイムに圧縮し異なるチップ間のデータ伝送速度を向上させることが可能なハードウェアモジュールの開発に成功している。
今後は、これらの成果を発展させるとともに、大規模かつ複雑化する計算機を効率よく利用し容易に性能を引き出すことができるような処理系の研究開発に取り組む。また、半導体の微細化技術が停滞する近い将来において有効な、新しい並列計算モデルとアーキテクチャの確立をめざす。
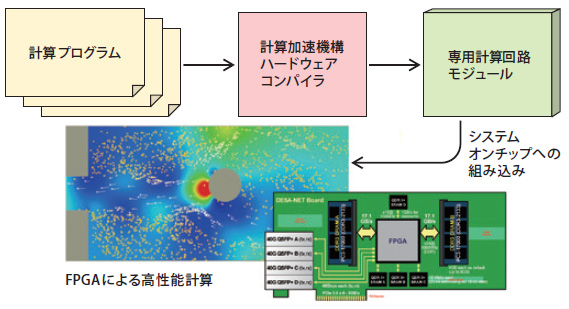
専用ハードウェア構造への変換による高性能計算の実現
2017年12月15日 第17回PCクラスタシンポジウム 基調講演,パネリスト
FPGA Shell for HPC, Argonne National Laboratory
FPGA Overlay Architecture and HLS Compiler, Tohoku University and Nagasaki University
