


- メニュー
宇宙とスパコン

138億年前に誕生した宇宙。その進化の過程は多くの謎に満ちています。進化の過程で起こったさまざまなイベントを理解するために、科学者たちは、古くから天体を観測し、理論を立ててきました。やがて、そこにコンピュータ・シミュレーションが加わりました。宇宙の研究の発展に、スパコンはどのように関係してきたのでしょうか。いくつかのテーマについて、見ていきましょう。
関連する課題:重点課題(9)宇宙の基本法則と進化の解明
萌芽的課題(3)太陽系外惑星(第二の地球)の誕生と太陽系内惑星環境変動の解明
星の構造と超新星爆発
宇宙の研究は、科学の中では真っ先にコンピュータが採り入れられた分野の1つです。コンピュータがアメリカで誕生したのは1940年代ですが、それからまもない1950年代には、すでに星(恒星)の内部構造のシミュレーションが行われました。行ったのは、ドイツ系アメリカ人でプリンストン大学教授のシュワルツシルトです。
星はガスの集まりで、水素の核融合反応のエネルギーで輝いています。当時、さまざまな星の観測から、太陽程度の質量の星は、水素が燃え尽きると赤色巨星に変わると考えられていましたが、そのしくみはわかっていませんでした。そこでシュワルツシルトは、星が完全な球で、核融合で生じた熱が中心から外に等方的に伝わると仮定して(1次元球対称モデル)、星の構造の方程式を立て、数値計算を行って赤色巨星ができるしくみを研究しました。
日本を含む世界各国の研究者たちがこの研究を発展させ、現在では、1次元球対称モデルによる星の進化の理論は定性的には確立されています。2011年には、星の構造と進化を計算できるMESAというソフトウェアが公開され、研究者に利用されています。教科書に書かれているような星の進化の道筋はシミュレーションで確かめられ、太陽の寿命が約100億年であることもシミュレーションで明らかになったのです。
しかし、太陽の8倍以上の質量の星が一生の最後に起こす超新星爆発のシミュレーションは、まだ研究が進んでいる段階です。爆発のメカニズムとして有力視されている「ニュートリノ加熱説」では、終末期の星の中心で生じるエネルギーをニュートリノが外側へと運ぶことで、爆発が起こるとされています。このメカニズムのシミュレーションには膨大な計算が必要なため、詳細なシミュレーションが可能になったのは2000年代になって高性能のスパコンが登場してからです。
まず、1次元球対称モデルによる計算が行われましたが、爆発は起こりませんでした。2005年ごろからは、星が球ではなく回転楕円体だとする2次元モデルでの計算が行われ、対流の効果が重要だと指摘されました。しかし、2次元計算では対流を正しく取り扱うことができませんでした。
そこで、日本のグループは「京」を使って3次元モデルでのシミュレーションに取り組み、ライバルだったドイツやアメリカのグループに先駆けて超新星を爆発させることに成功しました(『計算科学の世界』第9号「超新星爆発を『京』で再現」参照)。2014年のことです。しかし、爆発のエネルギーは観測よりもずっと小さいものでした。その理由は、ニュートリノの動きが十分に再現されていないためだろうと考えられています。
ニュートリノは、さまざまな大きさのエネルギーをもち、さまざまな方向に進みます。1次元での計算でも、「京」での計算でも、ニュートリノのエネルギーを多数の段階に分け、低エネルギーのニュートリノほど物質と反応しにくく抜け出しやすいことをきちんと考慮しています。しかし、ニュートリノがさまざまな角度で進むことをシミュレーションに採り入れるには、「京」でも計算性能が不足していたため、平均した角度で代表させていました。そこで、ポスト「京」では、100通りほどの角度について計算を行い、より現実に近い超新星爆発を起こすことをめざしています。
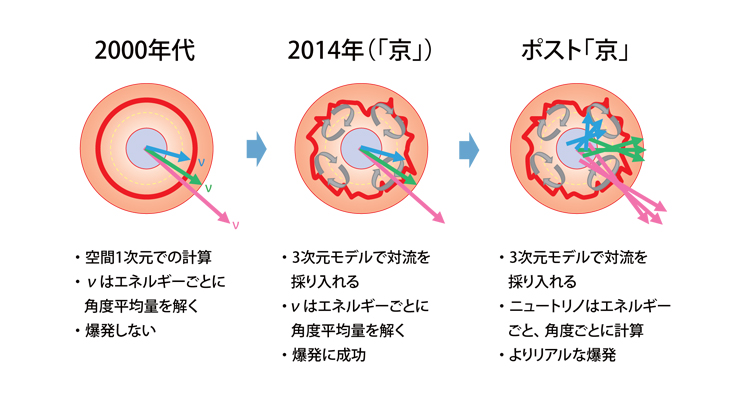
超新星爆発のシミュレーション(提供:国立天文台滝脇知也助教)
2000年代になってから詳細に計算できるようになったが、「京」で3次元モデルの計算を行うことで、初めて爆発の再現に成功した。1次元での計算と「京」での計算では、ニュートリノ(ν)が平均した方向に進むとしている(図の3本の矢印。エネルギーはピンク、緑、青の順に高くなり、エネルギーの低いニュートリノほど抜け出しやすいことを表している)。少し右に進むニュートリノと少し左に進むニュートリノは、本来すれ違うはずだが、これまでは右と左を平均した方向にいくものと仮定して、計算していた。ポスト「京」では、あらゆる方向に進むニュートリノを採り入れることで、より現実に近い爆発の再現をめざす。
惑星の起源の解明
太陽系の惑星がどのようにしてできたのかも、シミュレーションの重要なテーマの1つです。
惑星形成の理論として現在標準的なのは、京都大学の林忠四郎らが1980年代に完成させた「京都モデル」です。これは、(1)太陽ができたときの副産物として、ガスとダストからなる原始太陽系円盤ができる、(2)ダストが太陽の周りを公転しながら集まって微惑星ができる、(3)微惑星が衝突合体して原始惑星ができる、(4)原始惑星どうしが衝突して地球型惑星ができる一方、原始惑星がガスをまとって木星型と海王星型の惑星ができる、というものです。
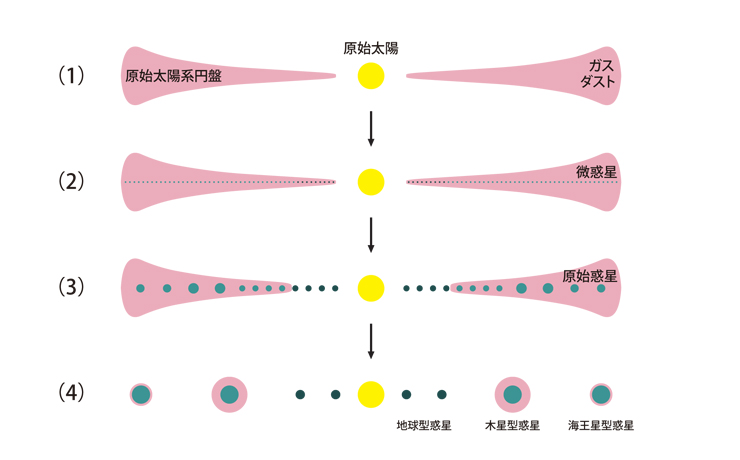
京都モデル(提供:国立天文台小久保英一郎教授)
1980年代に京都大学のグループが確立し、現在、惑星形成の標準的な理論となっている。
しかし、この理論にはいくつかの問題があります。例えば、微惑星がぶつかる過程のモデル方程式を解くと、地球は10億年ほどでできるのですが、木星ができるには太陽系の年齢よりも長い時間がかかってしまいます。この問題が起こるのは、理論モデルをつくるときに、微惑星がみな同じ大きさで、同じように成長すると仮定しているからです。
そこで、1980年代の中頃から、もっと現実的なモデルでシミュレーションを行って、メカニズムを理解しようという試みが始まりました。まずアメリカで、微惑星の質量にばらつきを採り入れ、質量が異なると軌道が異なることを考慮してシミュレーションが行われました。これにより、重い微惑星は育ちやすく、軽いものは育ちにくいことが明らかになりました。育ちやすいものがタネになれば惑星の形成は速くなります。さらに、1980年代末には、微惑星を質量分布で表す近似的なシミュレーションではなく、一つひとつの微惑星が重力で引き合って運動し、衝突するようすを再現するシミュレーションが世界のいくつかのグループで始まりました。
3個以上の粒子の間に重力が働くとき、粒子の運動を表す方程式を解析的に解くことはできません(多体問題)。このため、まず、2個の粒子のすべての組み合わせについて重力を計算します。そして、ある1個の粒子にかかる重力の総和を求め、その粒子がどれだけ動くかを計算します。これを、すべての粒子について、時間を刻んで繰り返すのです。このシミュレーションは、重力N体シミュレーションと呼ばれますが、膨大な計算量が必要になります。そこで、専用計算機として、1989年から東京大学でGRAPEというシリーズが開発されました。
GRAPEを用いた惑星形成の研究は世界をリードし、1990年代後半に行われたシミュレーションの結果、ある条件の下で、京都モデルにより、惑星の形成をある程度再現できることがわかりました。(GRAPEは、惑星形成だけでなく、球状星団の進化、銀河の形成、銀河団の形成など、さまざまなシミュレーションに威力を発揮してきました。現在は国立天文台に最新の後継機が置かれています。)
しかし、京都モデルには、もう1つ大きな問題があります。原始惑星が月ぐらいの大きさまで成長すると、周囲のガスの抵抗を受けて公転が遅くなり、太陽に向かって落ちてしまうのです。その理由はまだわかっていません。ただし、太陽に向かって落ちるという結果は、一様に広がったガスの中に原始惑星が1個だけあるという理想化したモデルで方程式を解いたときに得られるので、このモデルをもっと現実的にしてシミュレーションを行うことで、実際にはそうならない理由がわかってくるのではないかと期待されています。
そこで、「京」を使い、原始惑星が周囲の微惑星と衝突しながら公転するというモデルでシミュレーションが行われました。この計算では、太陽に向かって落ちないケースもあることが確かめられています。さらに、ポスト「京」では、ガスの分布や、太陽の近くや太陽系の外周ではガスが電離するという現象も採り入れ、よりリアルなシミュレーションに挑む予定です。
宇宙の大規模構造を描き出す
宇宙には銀河が数え切れないほどありますが、その分布には偏りがあり、銀河の集団である銀河団をほかのたくさんの銀河が網目のようにつないでいます。この構造は、銀河の網羅的な観測により1980年代に発見され、「宇宙の大規模構造」と呼ばれています。そして、この構造がどのようにしてできたのかは、近年の宇宙分野のシミュレーションの大きなテーマとなっています。
大規模構造のもとは、宇宙が誕生したころにあった物質密度のわずかなゆらぎだと考えられています。周囲よりも密度が少し高いところは重力も少し大きいので、周りの物質が引き寄せられます。これが繰り返されて、密度の高い部分はどんどん密度が高くなっていきます。同時に、宇宙は膨張を続け、138億年かけて現在のような大規模構造ができたというわけです。
ここでいう「物質」とはおもに「ダークマター」のことです。これは、周期表の元素からなる「普通の物質(バリオン)」とはまったく別物で、目には見えず、正体はまだ不明で、重力だけを及ぼす物質です。宇宙全体ではダークマターはバリオンの5倍以上存在し、ダークマターが集まったところにバリオンのガスが引き寄せられて、星や銀河が生まれたと考えられています。つまり、大規模構造をつくっている主役はダークマターなのです。
宇宙誕生後38万年のダークマターの分布は、衛星観測で詳しく調べられています。そこで、観測データから判明した生まれたての宇宙の状態を出発点として、シミュレーションを行い、現在の宇宙の大規模構造が再現されるかを調べます。ただし、密度のゆらぎは波のように連続しています。コンピュータは波を扱うのがあまり得意ではないので、波を粒子の分布に置き換えます。そうすれば、微惑星のときと同じような重力N体シミュレーションが可能になります。これを宇宙論的N体シミュレーションと呼びます。
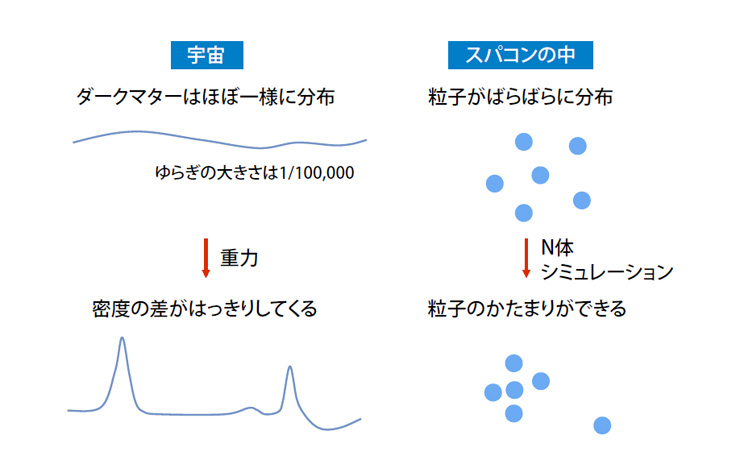
宇宙論的N体シミュレーション(提供:東京大学吉田直紀教授)
ダークマターの分布を粒子の集まり具合で表し、この粒子について重力N体シミュレーションを行う。
宇宙の構造を再現しようというシミュレーションは、宇宙の大規模構造が発見される前の1970年代から始まりました。当初は、ダークマターの密度ではなく、一つひとつの銀河を粒子で表し、銀河団の形成をシミュレーションする研究が多く行われました。扱える銀河の数は数百個でした。1980年代になってから、ダークマターを扱うシミュレーションのほうが主流になりました。
その後、コンピュータの進歩と計算法の進歩があいまって、計算できる粒子の数は指数関数的に増え、40年間で10億倍になりました。粒子数が増えたとき、同じ範囲ならより細かく見ることができ、同じ解像度ならより広い範囲を見ることができるようになります。シミュレーションの進化により、宇宙の大規模構造はかなりよく再現できるようになってきました。そして、2012年には、「京」を使って2兆個のダークマター粒子のシミュレーションが行われ、これまでにない細かさで、宇宙の構造ができていくようすが描き出されました(『計算科学の世界』第5号「スーパーコンピュータの中に「宇宙」を生みだす。」参照)。
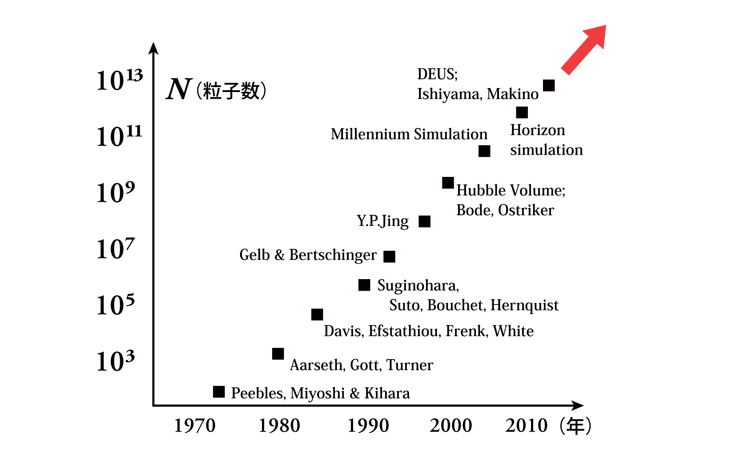
宇宙論的N体シミュレーションの進化(提供:東京大学吉田直紀教授)
シミュレーションで計算できる粒子の数(N)は年代とともに指数関数的に増えてきた。■の脇には計算を行った研究者またはプロジェクト名を記してある。宇宙論的N体シミュレーションの進化には、黎明期から多くの日本人研究者が貢献してきた。いちばん右上が、「京」で行われた2兆個の粒子のシミュレーション。
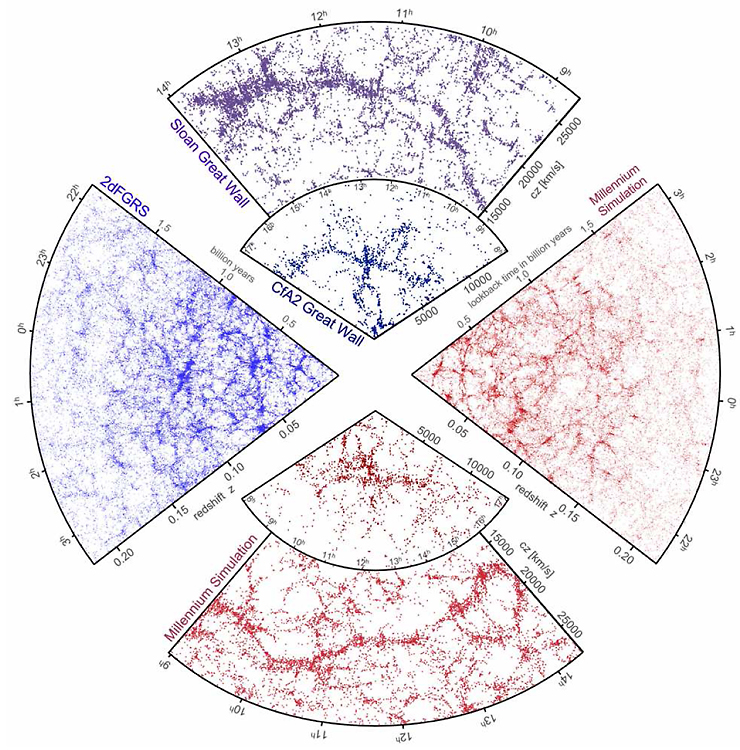
宇宙の大規模構造の観測とシミュレーション (Volker Springel, Carlos S. Frenk & Simon D. M. White, Nature 440, 1137-1144 (27 April 2006), reprinted by permission from Macmillan Publishers Ltd, copyright 2017)
青が観測データ。3種類の扇形はそれぞれ異なる観測プロジェクトで得られたもの。赤は、国際的な研究グループ「Virgo」が2005年に行った「ミレニアム・シミュレーション」の結果。このシミュレーションでは、1辺が20億光年の立方体の中で、100億個以上の粒子の分布がどう変化するかをシミュレーションした。3種類の観測データと似た部分をそれぞれとりだしてある。マックス・プランク協会の並列計算機IBM p690の512のプロセッサを使用し(0.2テラフロップス)、28日間かけて計算された。
宇宙との対話は続く
「京」からポスト「京」へと、スパコンの計算性能があがっていく中で、今後、宇宙の構造の進化に関してどのようなシミュレーションが計画されているのでしょうか。いくつかご紹介しましょう。
1つは、銀河系のダークマター分布の非常に詳細なシミュレーションです。ダークマターは理論的に存在するとされていますが、まだ発見されていません。観測しようにも、そもそもどこにあるのかがわかりません。そこで、詳細なシミュレーションでダークマター密度の高い場所を推定しようという研究が始まっています。そこを観測すれば、ダークマターの痕跡を発見できる可能性が高いと考えられるからです。
もう1つは、ダークマターのかたまり(ハロー)にバリオンのガスが引き寄せられて、星や銀河が形成される過程のシミュレーションです。星や銀河は互いに影響し合いながら生まれるので、一つひとつをとりだすのではなく、宇宙の広い空間の中でシミュレーションを行います。ダークマター粒子が重力で集まっていくのに合わせて、ガスの振る舞い、化学反応、エネルギー収支を計算することで、星や銀河の形成を再現することをめざしています。扱う現象が複雑で空間も広いため、膨大な計算が必要となります。

渦巻銀河形成のシミュレーション(提供:国立天文台4次元デジタル宇宙プロジェクト)
このシミュレーションは、ダークマターが集まったところにガスが集まり、小さな銀河ができて合体し、大きな銀河ができるようすを再現している(掲載図は動画の一場面)。1辺が30万光年の立方体の中で、100万個のダークマター粒子、100万個のバリオン粒子を用いて計算した。計算機はGRAPE-5を用い、2003年10月から10ヵ月間かかった。シミュレーションを斎藤貴之(2017年4月現在、東京工業大学)、可視化を武田隆顕、額谷宙彦が担当した(敬称略)。このようなシミュレーションを、もっとたくさんの粒子を使い(解像度を上げ)、10億光年程度のスケールで行うには、ポスト「京」のような高性能のスパコンが必要になる。
一方、これまでとは異なる手法として、観測ビッグデータの利用も計画されています。今後10 年の間に、世界中で広域宇宙探査計画が進み、銀河、ブラックホール、超新星などについて大量の観測データが集積される見込みです。これらのデータとシミュレーションを組み合わせることで、宇宙の進化と天体形成の解明をめざします。
宇宙の研究では、シミュレーション、理論、観測の三者が密接な関係をもちながら、理解が進んでいきます。研究者は、観測された現象を説明するために、物理学の法則に基づいて理論を立てます。その理論を方程式で表し、シミュレーションを行います。結果が観測と一致すれば、その現象を「理解した」といえます。シミュレーション結果が観測と一致しないときは、理論になにか足りないことがあるはずです。そこで、研究者は理論を考え直し、また、シミュレーションを行って、結果と観測を比べます。
このプロセスは、「私たちはこう考えているのですが、どうでしょうか?」とシミュレーションで宇宙に問いかけ、観測との一致具合という形で返事をもらう「対話」のようでもあります。研究者たちはこれからも宇宙との対話を続け、宇宙の理解を進めていくのです。