


- メニュー
気象予測とスパコン

気象学は、計算科学の中でも早くから研究が始まった分野の1つです。ここでは、計算による気象予測が発展してきた歴史をたどったのち、ポスト「京」で何をめざすのかをご紹介します。
関連する課題:重点課題(4)観測ビッグデータを活用した気象と地球環境の予測の高度化
明日の天気は計算でわかる?
現在の日本では、毎日の天気予報にスパコンが使われています。スパコンでいったい何を計算しているのでしょうか。
気象の基本となるのは大気の状態です。大気の状態は、気温、気圧、湿度、風速、風向などの物理量(数値)で表すことができ、これらの数値は、流体力学などの物理法則に基づいて時間とともに変化していきます。ですから、観測したデータを、物理法則を表す方程式に入れて計算すれば、未来の大気の状態を予測できるはずです。この考えに基づいて計算を行い、未来の気象を予測するのが「数値天気予報」です。スパコンは、数値天気予報のために使われており、その結果を採り入れて天気予報が行われているのです。
数値天気予報の概念は、コンピュータが登場するよりずっと前の1912年に、ノルウェーのビャークネスが提唱しました。そして、1920年ごろ、イギリスのリチャードソンが、世界で初めて数値天気予報を試みました。しかし、すべて手計算で行ったため、6時間分の予測をするのに2ヵ月もかかりました。さらに、最初に方程式に与えるデータ(初期値)が不適当だったため、現実に起こり得ない気圧の値が得られ、失敗に終わりました。

リチャードソンの夢(気象庁ホームページより)
リチャードソンは、「6万4000人が大きなホールに集まり1人の指揮者のもとで整然と計算を行えば、実際の時間の進行と同程度の速さで予測計算を実行できる」と考えた。
コンピュータが誕生したのは1940年代です。なかでも1946年にアメリカでENIACという大型コンピュータが完成すると、数値天気予報の「実験」が企画され、1950年に成功しました。企画したのは、フォン・ノイマンという有名な数学者で、多くの気象学者が参加しました。この実験には、ENIACの性能を確かめるという意味もあったと言われています。
その後、各国で研究が進み、1954年に世界で初めて、気象当局による業務としての数値天気予報がスウェーデンで行われました。1955年にはアメリカで、そして、1959年には日本と旧ソ連でも、業務としての数値天気予報が始まりました。このとき気象庁に導入されたコンピュータはIBM704という、当時としては高性能のもの(現在のパソコンよりもはるかに性能は低いですが)で、日本の官庁に初めて導入された大型汎用コンピュータでした。

数値天気予報開始当時、気象庁に導入されたコンピュータ(気象庁ホームページより)
コンピュータとともに進歩してきた数値天気予報
しかし、当時の数値天気予報の精度は低く、実際の天気予報に採り入れられるようになるまでには、長い年月がかかりました。
数値天気予報の原理はわかりやすいのですが、実行するのは簡単ではありません。まず、大気という連続的なものを、とびとびの値しか扱えないコンピュータでどのように計算するのかという問題があります。このため、大気を格子で区切り、その格子点がもつ物理量で、格子を代表させるという方法がとられます。
次に、その格子をどのぐらい細かくするかという問題があります。大気は地球を丸ごと包んでおり、地球の表面積は5億1000万km2【2は上付】もあります(大気の厚さは10km程度)。格子を細かくすれば気象現象をより詳しく捉えられますが、格子点が増え、計算量も増えてしまいます。
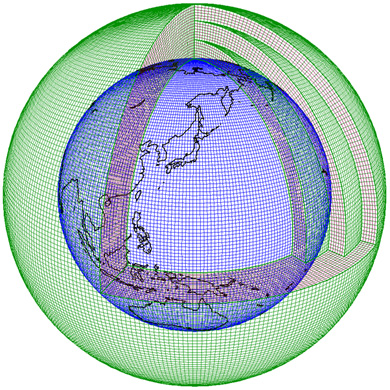
数値天気予報に使われる格子の例(気象庁ホームページより)
そして3つめの問題は、気象にはたくさんの物理現象が関係していることです。気象の基本となる大気の状態変化は、いくつかの比較的簡単な方程式で表すことができ、数値天気予報の骨格となっています。しかし、格子の大きさよりも小さい範囲で起こる現象は、この方程式では計算できません。また、水蒸気が凝結して雲ができ、雲粒が発達して雨になるといった、水の状態変化がかかわる現象は、方程式で表しきれない部分もあります。そこで、数値天気予報では、こうした現象を計算に採り入れるため、「パラメタリゼーション」という方法が使われます。状態を表す数値を厳密な方程式から求めるのではなく、「こういう条件のときはこういう値になる」というようにパラメーター化した項を方程式に付け加えるのです。
研究者たちは、その時代のコンピュータの計算能力をにらみながら格子のサイズを決め、目的に応じて骨格となる方程式を選び、どんなパラメタリゼーション項を付け加えるのが適切かを考えてきました。このようにしてできあがった方程式のセットを「気象モデル」と呼びます。
数値天気予報が始まってからの歴史を振り返ると、コンピュータの性能が上がることで、気象モデルによる計算をより細かい格子の上で行えるようになり、また、計算できる領域も半球から全球へというように広がって、より精度の高い予測ができるようになってきたことがわかります。「数値天気予報の歴史はコンピュータの歴史である」といっても過言ではないのです。
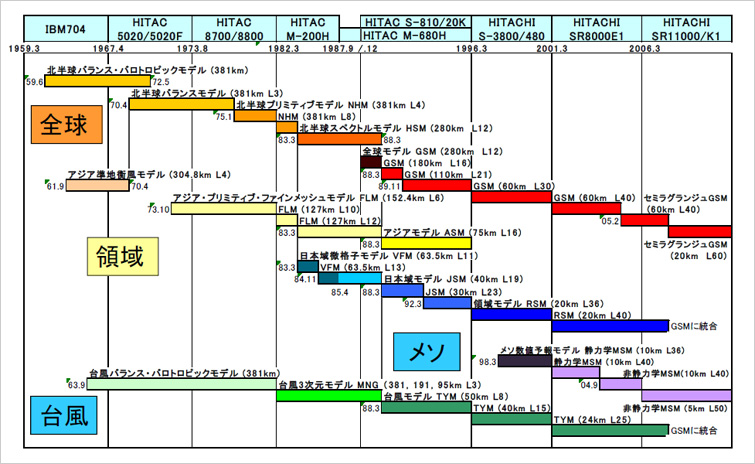
気象庁で使われてきたコンピュータと気象モデルの歴史(気象庁ホームページより)
気象庁では、目的ごとに対象領域の広さの異なる気象モデルを使用しており、それぞれが計算機の進歩とともに、進歩してきた。この図は2009年までの歴史をまとめたもので、最上段にコンピュータの機種、各バーの上に気象モデルの名称と格子のサイズ(水平方向の格子間隔と、鉛直方向の層の数)が書かれている。
見方を変えると、コンピュータの進歩は、気象モデルの進歩を促してきたとも言えます。実は、大きな格子を想定してつくった気象モデルによる計算を、小さな格子の上で行うと、おかしな結果が得られる場合があります。これは、大きな格子と小さな格子で表現される現象が違ってくるために起こります。このような場合、研究者は、気象モデルを見直して方程式に修正を加えるのです。
「京」で進んだ気象への理解
「京」は、上で述べた「気象モデルの進歩」に貢献する成果をあげてきました。
その1つとして、水平方向の格子間隔870mという細かい格子(それまでの最高は3.5km)で、全球の大気のシミュレーションに世界で初めて成功したことがあげられます。一つひとつの積乱雲はサイズが数km程度であるため、これまでの格子ではきちんと表現できなかったのですが、このシミュレーションでは、1個の積乱雲を複数の格子点で表現することができ、たくさんの積乱雲の集まりとも言える台風の構造も精度よく再現できました。
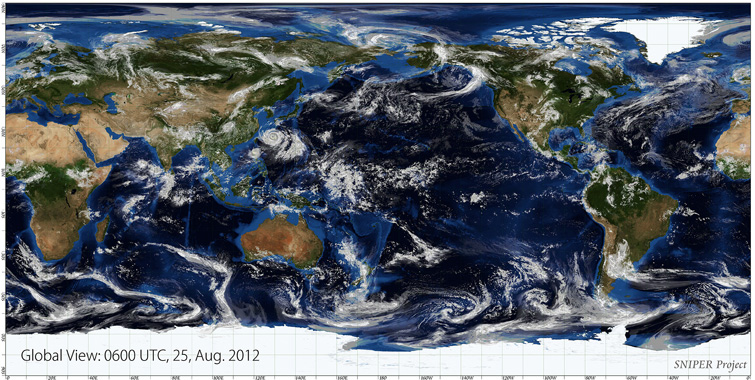
格子間隔870mでの全球シミュレーション
2012年8月25日00時の気象データを初期値としてシミュレーションした結果(6時間後)。大気の流れ、台風15号の構造などが、精度よく再現されている。
この結果は、格子を細かくとり、その格子サイズに適した気象モデルを開発することで、現実に起こっている現象をより詳細に再現でき、気象への理解が深まることを示しています。ただし、格子を細かくとると計算量は跳ね上がります。このシミュレーションは、「京」を使ったからこそ成功したのです。
このシミュレーションを実際の天気予報に使ったらどうかと思う人もいるかもしれません。しかし、新たな気象モデルが数値天気予報に使われるようになるまでには、10年以上の時間がかかるのが普通です。また、「京」なみの能力をもつスパコンが天気予報の現場に導入されるまでにも、かなり時間がかかると予想されます。ですから、「京」の成果がすぐに数値天気予報に使われるわけではありません。しかし、その成果は予報業務の現場にも影響を与え、将来の数値天気予報を変えていくことでしょう。最先端の研究とはそういうものなのです。
ポスト「京」は命を救う数値天気予報をめざす
ポスト「京」では、「京」とは少し視点を変え、観測データの取り込みに重点をおいた研究開発が行われます(重点課題(4)サブ課題A 革新的な数値天気予報と被害レベル推定に基づく高度な気象防災)。対象とするのは、気象衛星やレーダーによって観測されるビッグデータです。
2015年7月に運用が開始された気象衛星ひまわり8号は、ひまわり7号の約50倍のデータを送ってきます。また、最新のフェーズドアレイ気象レーダーはこれまでの約100倍のデータを取得します。このように、従来とは桁違いの量の観測データが集まる時代になったからこそ、ポスト「京」の性能を活かして、すばやい数値天気予報を可能にしようというわけです。
研究テーマの1つは、豪雨の予測です。2014年8月の広島での豪雨、2015年9月の関東・東北豪雨では、夜間に土砂崩れが起こったことで多くの方が亡くなりました。そうした被害を防ぐためには、昼間のうちに避難できるように、より早い時点での予測が必要です。しかし、このような豪雨をもたらす雲は、亜熱帯から伸びる「湿舌」に由来し、これまでの観測データではとらえることが難しいものでした。

2014年8月の広島での豪雨による土砂災害現場(気象庁ホームページより)
そこで、ポスト「京」では、観測ビッグデータを活用した数値天気予報により、このような集中豪雨の発生をいちはやく予測することをめざしています。カギとなるのは、データ同化技術の高度化です。気象モデルによる計算では、最初に観測データを与えるだけでなく、計算の途中でも、その時点の観測データと照らし合わせて「軌道修正」をします。これがデータ同化です。10分おきに送られてくるひまわり8号のデータをはじめ、大量のデータがどんどん送られてくる状況で、データ同化をいかに行うのか。研究者たちの挑戦が始まります。
この研究開発が成功し、豪雨がどこをおそうのかが半日前にわかるようになれば、豪雨による被害を軽減することが可能になります。「京」の成果と同様、これも、すぐに天気予報の現場で使われるという性格のものではありませんが、気象予測の進歩を牽引する成果となることは間違いないでしょう。
遠い未来を予測する

地球シミュレータ(初代)(画像提供:海洋研究開発機構)
数値天気予報は、毎日の天気や長期予報の基礎となるだけでなく、長い年月にわたる気候変動の予測にも役立ちます。気候変動予測の基本は、気象モデルの計算を、格子を粗くして長い時間にわたって行うことですが、それだけでなく、植生やCO2濃度など長い時間をかけて変化する要素を採り入れます。このようなモデルを、地球システムモデルと呼んでいます。
日本では、2002年に完成し、同年から2004年まで演算速度世界一だった海洋研究開発機構の地球シミュレータ(初代)を用いて、2100年までの気候変動予測が行われました。2004年に発表されたその結果は、世界から注目され、人々の意識や政策にも大きな影響を与えました。