


- メニュー
コンピュータによる解析と予測に基づく効率的な医薬品開発

現在、薬の開発期間は11年から15年、開発費用は開発中止品の費用も含むと1品目当たり約500億円も掛かります。このため製薬会社の経済的負担が大きく、医療費も高くなり、私たちの負担増加にもつながります。また、希少疾患向けの新薬の開発が避けられてしまうことも少なくありません。
薬の開発の中心は、病気の原因タンパク質を見つけ出し、それに結合する新規化合物を創ることです。結合するかどうか、その結合の強さはどれくらいかを正確に把握することは重要なポイントです。しかし、タンパク質の種類は10万以上、化合物にいたっては10の60乗以上もあり、すべての化合物の薬効を実験で確かめるのは不可能です。
近年は、実験に加え、汎用コンピュータによるシミュレーションも行われ、科学的な解析に基づく結合予測は開発効率を向上させると期待されています。今回、圧倒的な計算パワーを持つ「京」が登場し、その計算能力の高さに加え、計算方法を工夫することにより、開発の成功率の向上、開発期間の短縮、またコスト低減の実現など、医薬品の開発効率の飛躍的な向上が期待されます。
より計算の高速化を目指して、タンパク質と化合物が結合するかどうかを効率的に予測するためにパターン認識技術を用いました。これはデジタルカメラにおいて大量の人の顔画像を読み込み、顔パターンの統計ルール化を行い、人の顔を自動認識する技術と同様の手法です。
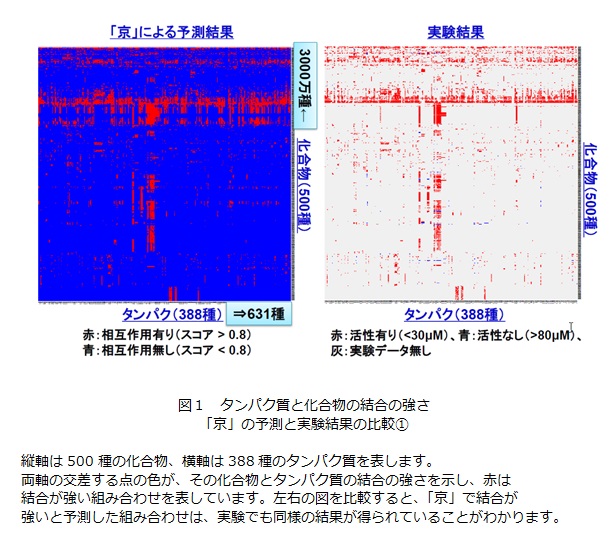
まず「京」に、すでに結合することがわかっているタンパク質と化合物の12万通りの結合組み合わせを読み込ませ、結合パターンの統計ルール化を行いました。このルールを用いて631種の疾患原因タンパク質と、3000万種の化合物の全組み合わせ(世界最大規模である189.3億通り) の結合予測を行いました。汎用コンピュータ(16ノード使用)では約2年掛かるところが、「京」をフルに使用すると、5時間45分で計算が終了します。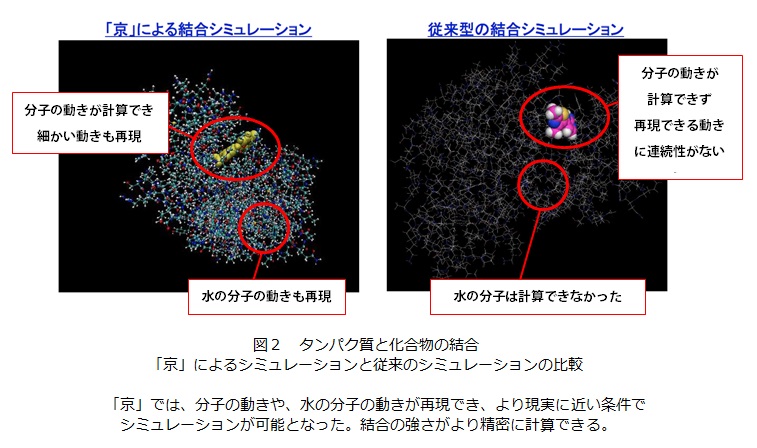
また、病気の原因タンパク質にだけ強く結合する化合物が、医薬品に適していると考えられ、結合の強さを求めることも重要です。これを精密に計算するには、分子の動きや溶媒(水分子)の影響も含めたシミュレーションが必要です。15個の化合物に対するタンパク質との結合強さの計算は、通常の汎用コンピュータであれば20年掛かりますが、「京」をフルに利用すると1週間程度で可能となりました。また、精度も上がるため、以前5%程度だった正答率を、将来的には70%まで上げたいと考えています。
このように「京」に化合物の化学構造とタンパク質の情報を入力すると自動的に結合の強さを計算することが可能となりました。将来的には病気の原因となるタンパク質をコンピュータに入力するとコンピュータ自らが適切な化合物を考えて自動的に分子設計するなど、革新的な医薬品開発の確立を目指します。
より数多くの化合物との結合計算を行うために、スパコンの高速化へのニーズは高く、今後の発展にも期待が寄せられています。
【京コンピュータシンポジウム2013講演などから抜粋】
関連記事
京コンピュータシンポジウム2013 講演要旨・講演資料
マイナビニュース・京を活用して新薬の開発効率を向上 - 京大
サイエンスニュース2012(動画) *登録要